Gruppo Aggrega↵
Abstract
Contiene funzioni che aggregano valori nei livelli e campi.
aggregate↵
Restituisce un valore aggregato calcolato usando elementi da un altro vettore.
Sintassi:
- aggregate(layer, aggregate,expression[,filter][, concatenator=''][,order_by)
[ ] indica componenti opzionali
Argomenti:
- layer una stringa, rappresentante o un nome di un layer o un ID di layer
-
aggregate una stringa corrispondente all'aggregato da calcolare. Opzioni valide sono:
- count
- count_distinct
- count_missing
- minimun or min (>= QGIS 3.36)
- maximun or max (>= QGIS 3.36)
- sum
- mean
- median
- stdev
- stdevsample
- range
- minority
- majority
- q1: primo quartile
- q3: terzo quartile
- iqr: inter quartile range
- min_length: minima lunghezza stringa
- max_length: massima lunghezza stringa
- concatenate: unisce stringhe con un concatenatore
- collect: crea una geometria multiparte aggregata
-
expression sotto-espressione o nome campo da aggregare
- filter espressione filtro opzionale per limitare gli elementi usati per calcolare l'aggregato. I campi e la geometria provengono dagli elementi del vettore unito. Si può accedere all'elemento sorgente con la variabile
@parent. - concatenator stringa opzionale da usare per unire i valori per il raggruppamento 'concatenate'
- order_by espressione filtro opzionale per ordinare gli elementi usati per calcolare il valore aggregato. I campi e la geometria provengono dagli elementi del vettore unito. Da predefinito, gli elementi verranno restituiti in un ordine non specificato.
Esempi:
aggregate(layer:='rail_stations',aggregate:='sum',expression:="passengers") → somma tutti i valori per il campo passengers nel layer rail_stations
aggregate('rail_stations','sum', "passengers"/7) → calcola la media giornaliera di "passengers" dividendo il campo "passengers" per 7 prima di sommare i valori
aggregate(layer:='rail_stations',aggregate:='sum',expression:="passengers",filter:="class">3) → somma tutti i valori per il campo "passengers" soltanto dagli elementi geometrie dove l'attributo "class" è maggiore di 3
aggregate(layer:='rail_stations',aggregate:='concatenate', expression:="name", concatenator:=',') → elenco separato da virgole del campo name per tutti gli elementi nel vettore rail_stations
aggregate(layer:='countries', aggregate:='max', expression:="code", filter:=intersects( $geometry, geometry(@parent) ) ) → Il codice Paese di un Paese di intersezione nel vettore 'countries'
aggregate(layer:='stazioni_rotaie',aggregate:='sum',expression:="viaggiatori",filter:=contains( @atlas_geometry, $geometry ) ) → somma tutti i valori del campo viaggiatori in rail_stations all'interno dell'elemento atlante corrente
aggregate(layer:='rail_stations', aggregate:='collect', expression:=centroid($geometry), filter:="region_name" = attribute(@parent,'name') ) → aggrega le geometrie dei centroidi delle stazioni ferroviarie della stessa regione dell'elemento corrente
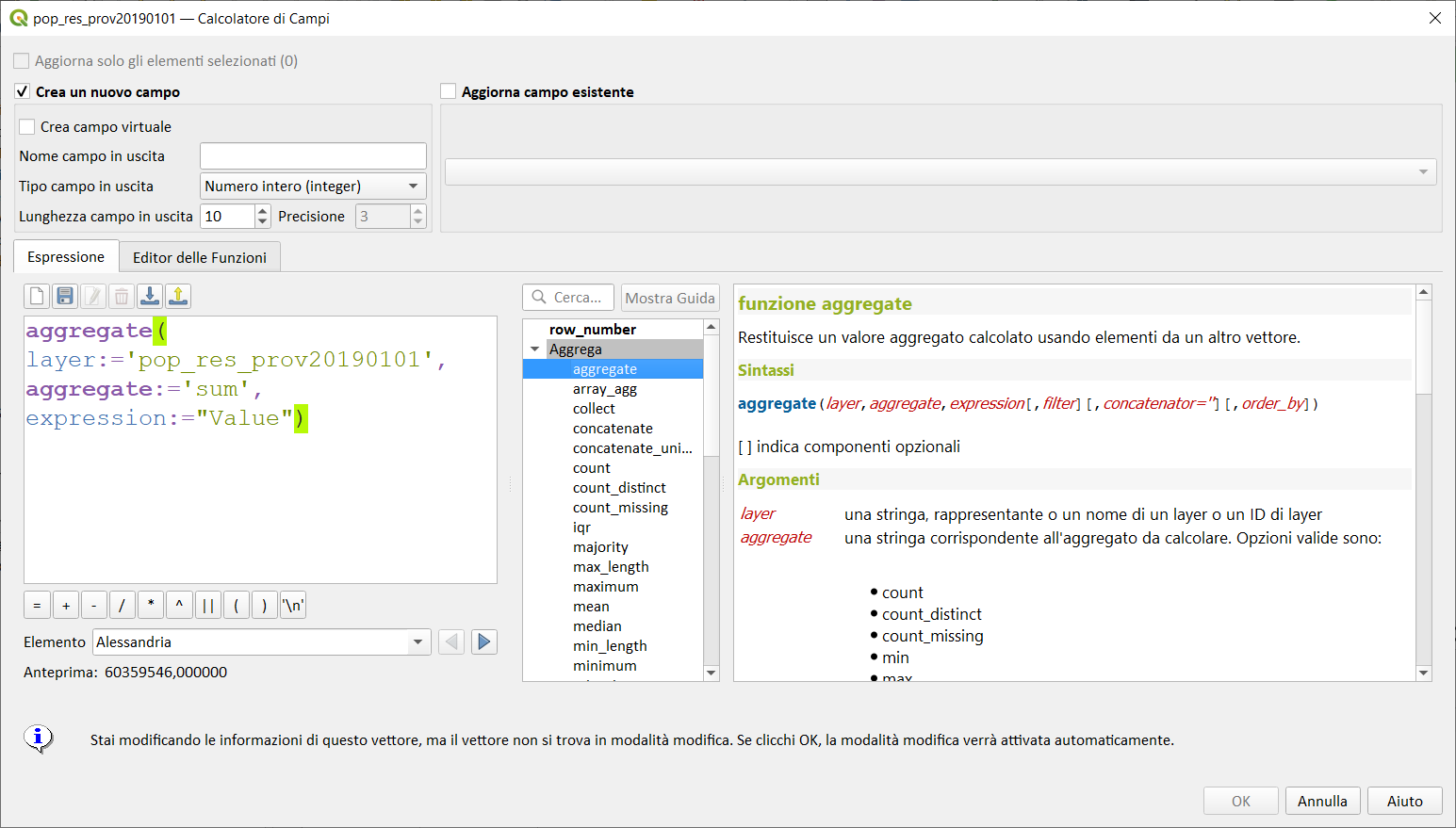
Osservazioni
i nomi dei layer vanno scritti tra apici semplici ('nome_layer') mentre i nomi dei campi con doppi apici ("nome_campo")
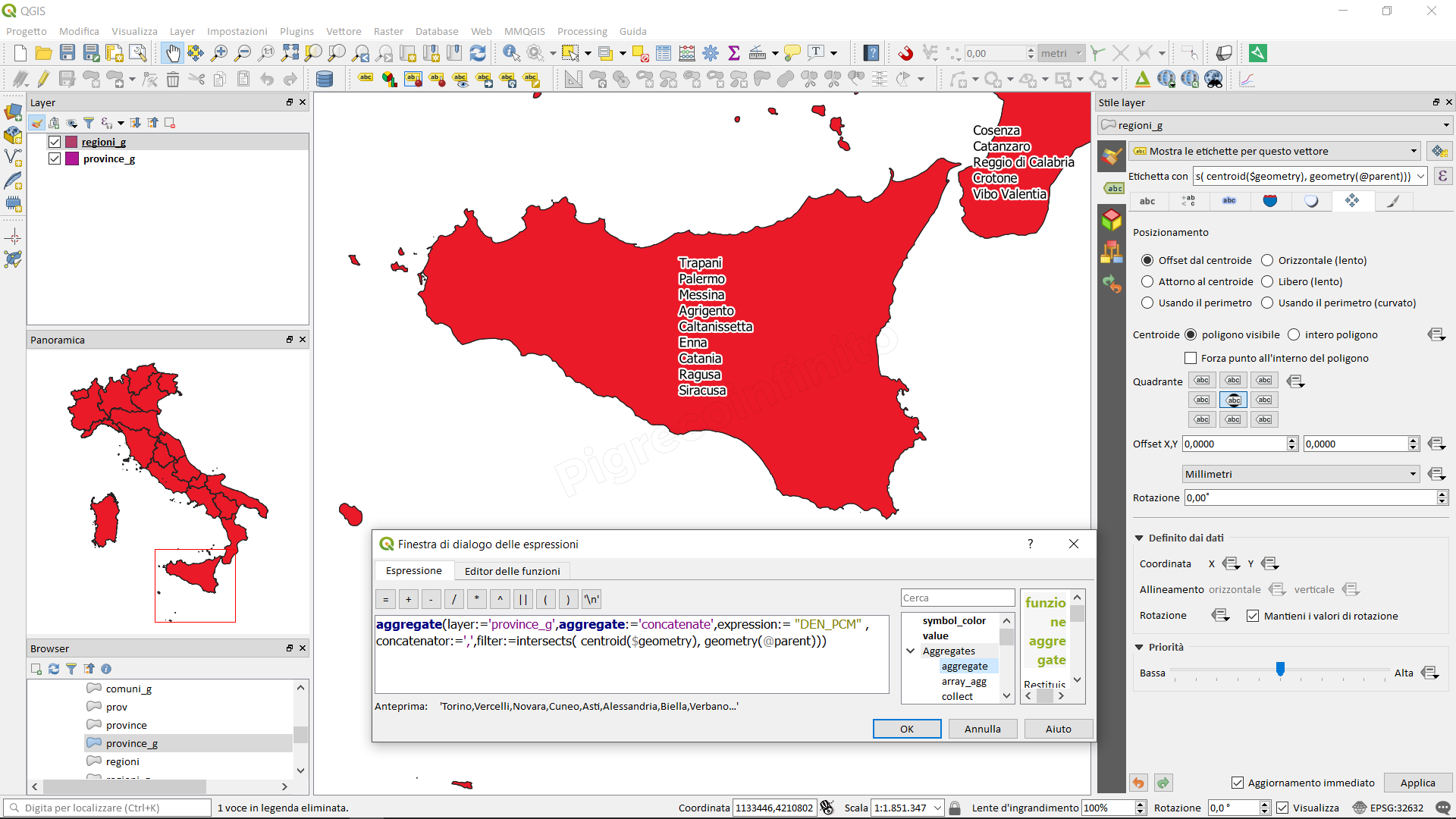
Altri esempi:
Come realizzare una spatial-join con aggregazione usando solo il calcolatore di campi qui
array_agg↵
Restituisce un array di valori aggregati da un campo o espressione.
Sintassi:
- array_agg(expression[,group_by][,filter][,order_by])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
- order_by espressione opzionale da usare per ordinare gli elementi usati per calcolare il valore aggregato. Da predefinito, gli elementi verranno restituiti in un ordine non specificato.
Esempi:
array_agg( "DEN_PCM" ,group_by:= "COD_REG" ) → lista di valori del "DEN_PCM", ragguppata per il campo "COD_REG"

Nota bene
Per prendere un valore specifico dell'array:
- array_agg("z")[0] → 148,03 è il primo valore dell'array, indice 0;
- array_agg("z")[1] → 164,21 è il secondo valore dell'array, indice 1;
- ecc...
dove "z" è un attributo
Osservazioni:
- la funzione
array_aggpermette di trasformare un attributo (colonna di una tabella) in un array!!! - la funzione attributes permette di trasformare una feature (riga di una tabella) in una maps e quindi in un array!!!
collect↵
Restituisce la geometria a parti multiple di geometrie aggregate da una espressione
Sintassi:
- collect(expression[,group_by][,filter])
Argomenti:
- expression espressione geometria da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
collect( $geometry ) → geometria a parti multiple delle geometrie aggregate
collect( centroid($geometry), group_by:="region", filter:= "use" = 'civilian' ) → centroidi aggregati degli elementi civili basati sul relativo valore regionale
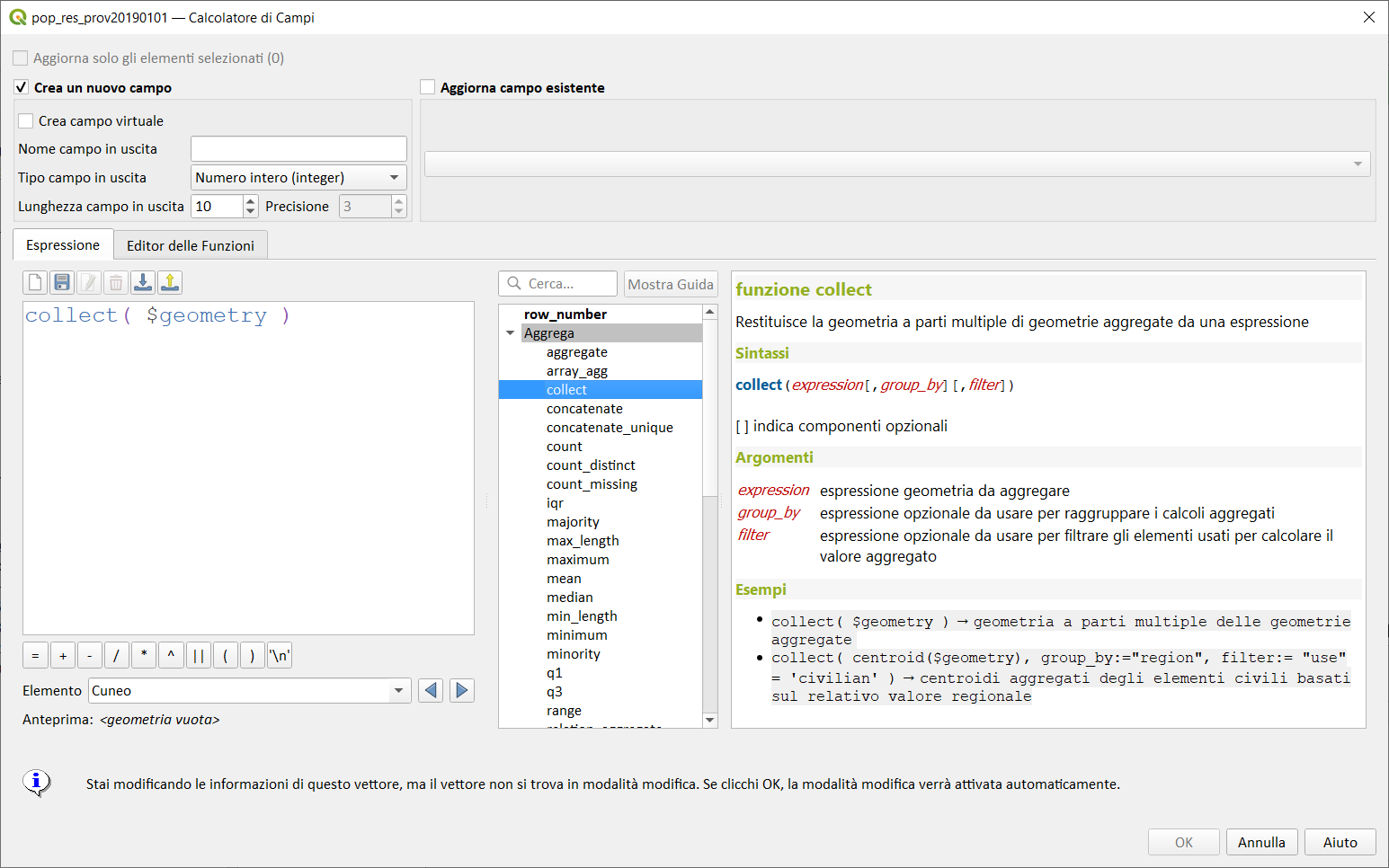
--
estrae i bounding box, uno per ogni geometria:
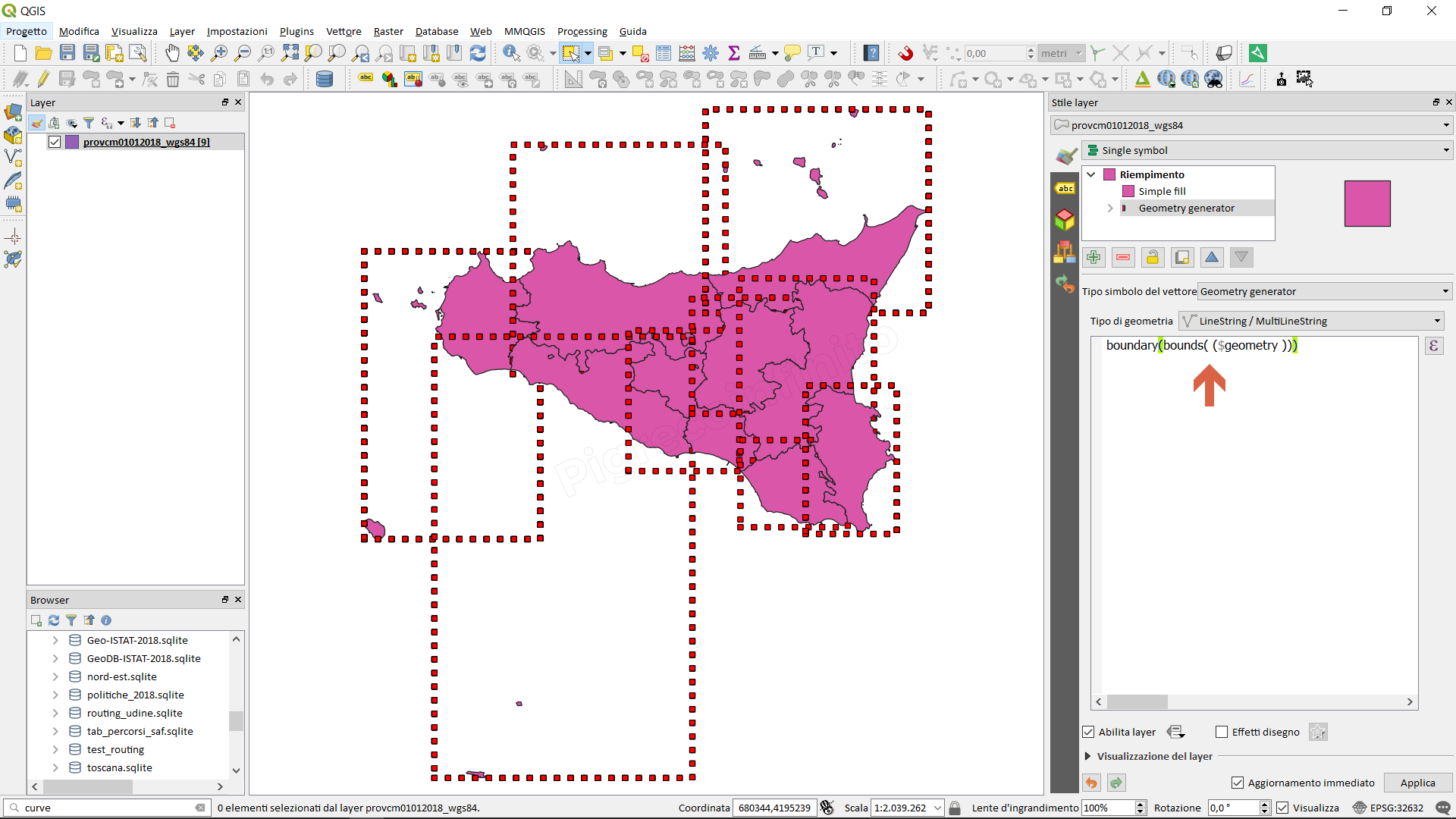
estrae il bounding box, dopo aver unito tutte le geometrie:
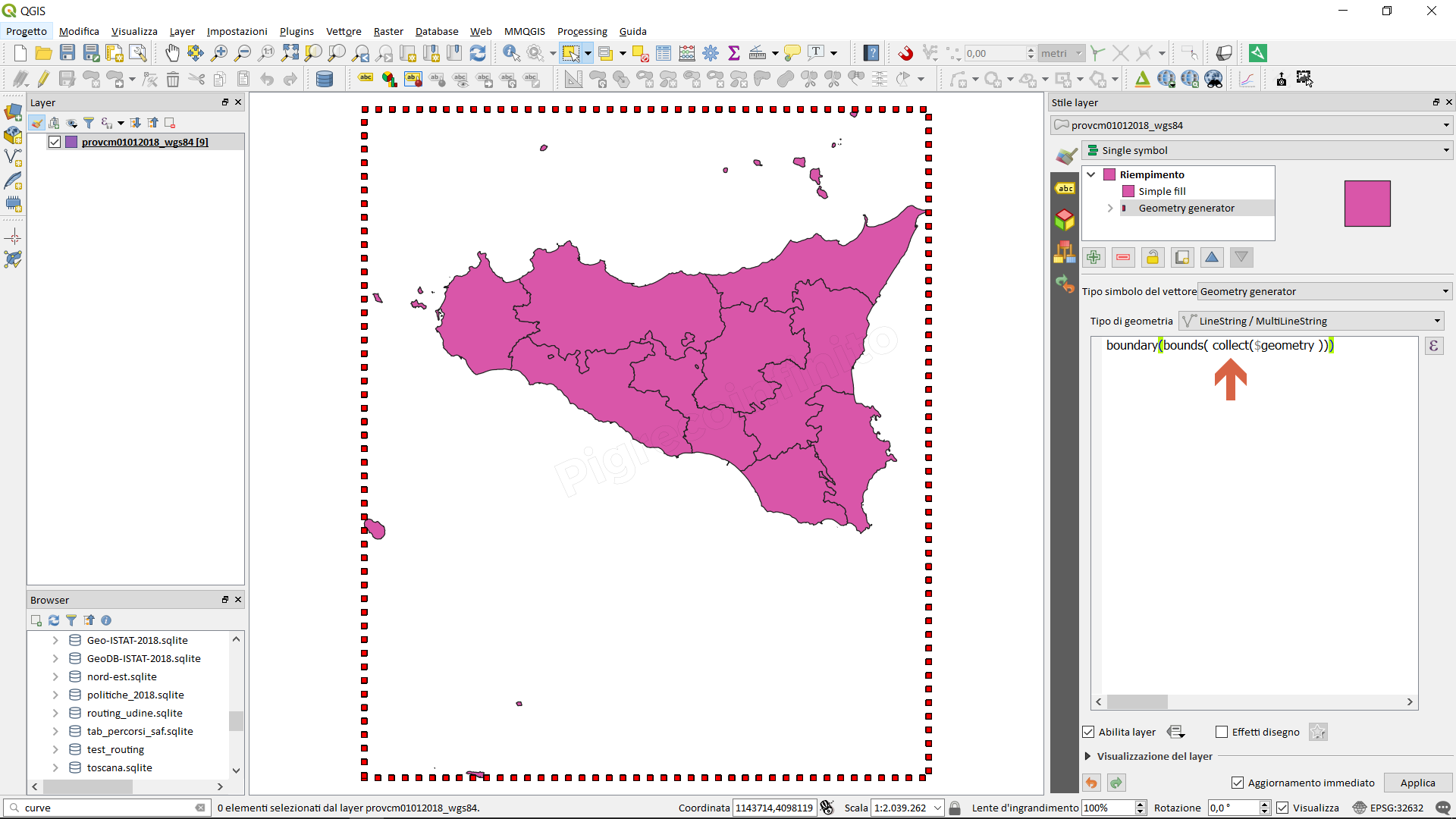
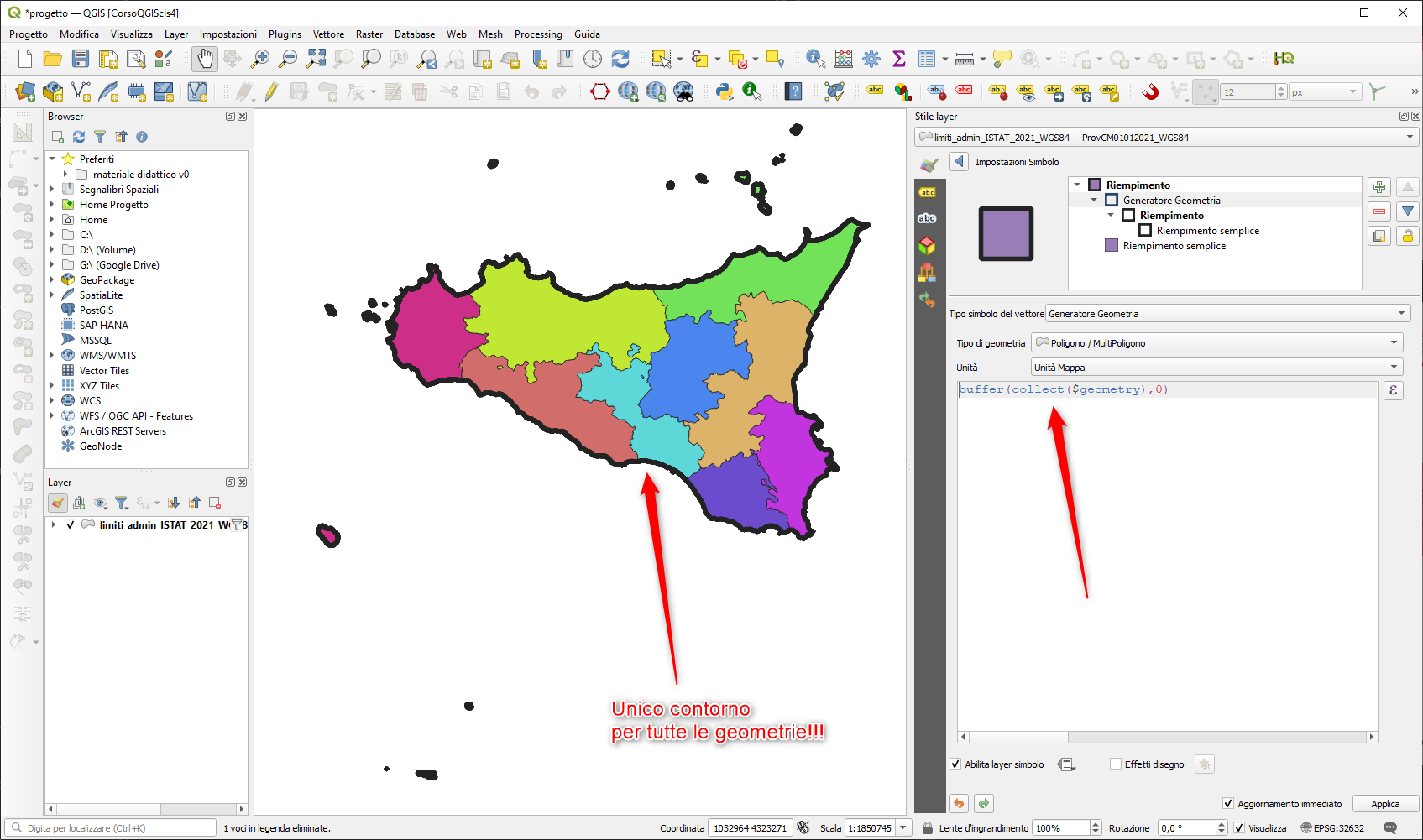
estrae il perimetro (unico per tutte le geometrie), dopo aver unito tutte le geometrie:
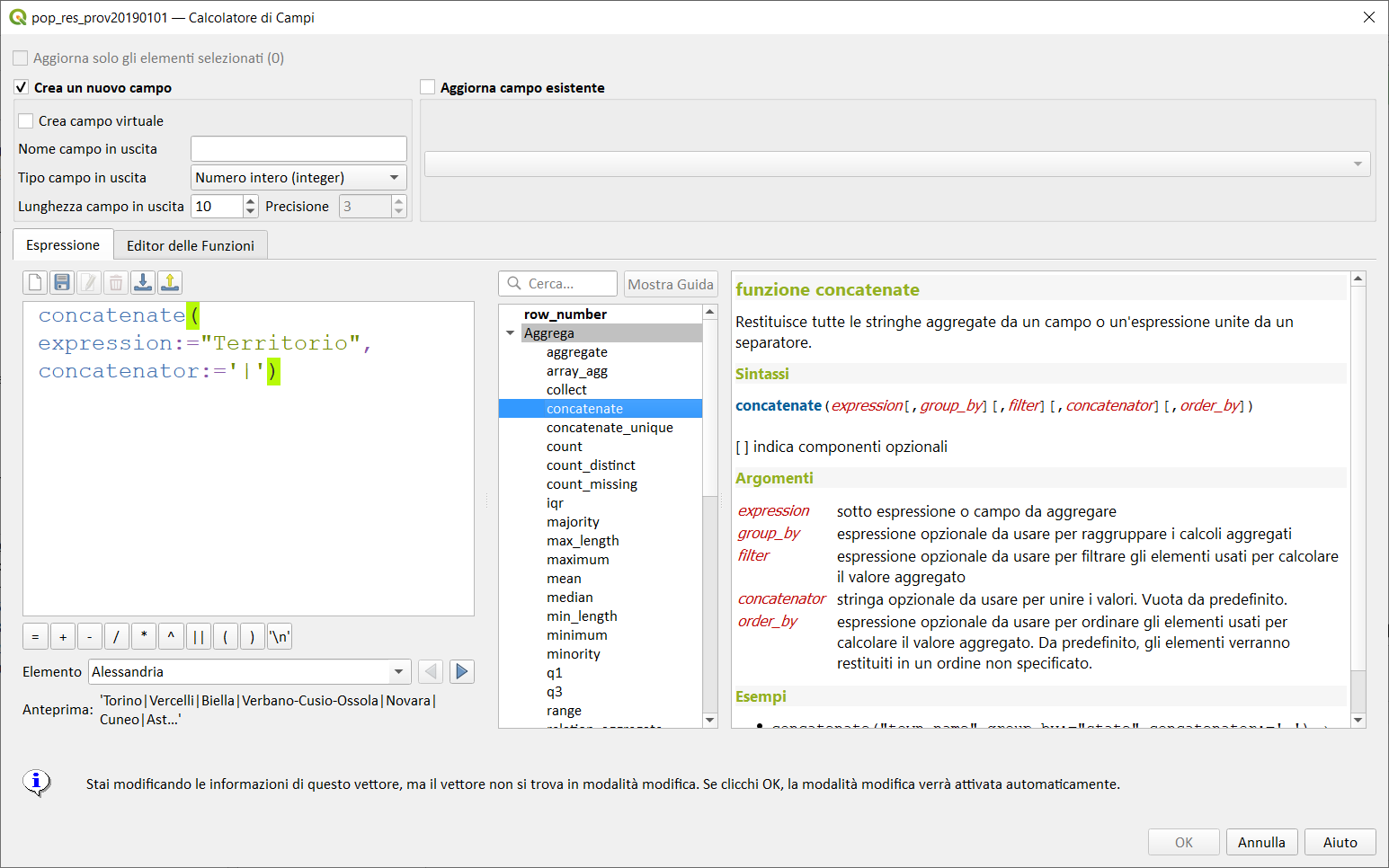
concatenate↵
Restituisce tutte le stringhe aggregate da un campo o un'espressione unite da un separatore.
Sintassi:
- concatenate(expression[,group_by][,filter][,concatenator][,order_by])
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
- concatenator stringa opzionale da usarsi per unire i valori
- order_by espressione opzionale da usare per ordinare gli elementi usati per calcolare il valore aggregato. Da predefinito, gli elementi verranno restituiti in un ordine non specificato.
[ ] indica componenti opzionali
Esempi:
concatenate("town_name",group_by:="state",concatenator:=',') → lista separata da virgola di town_names, raggruppata per campo state
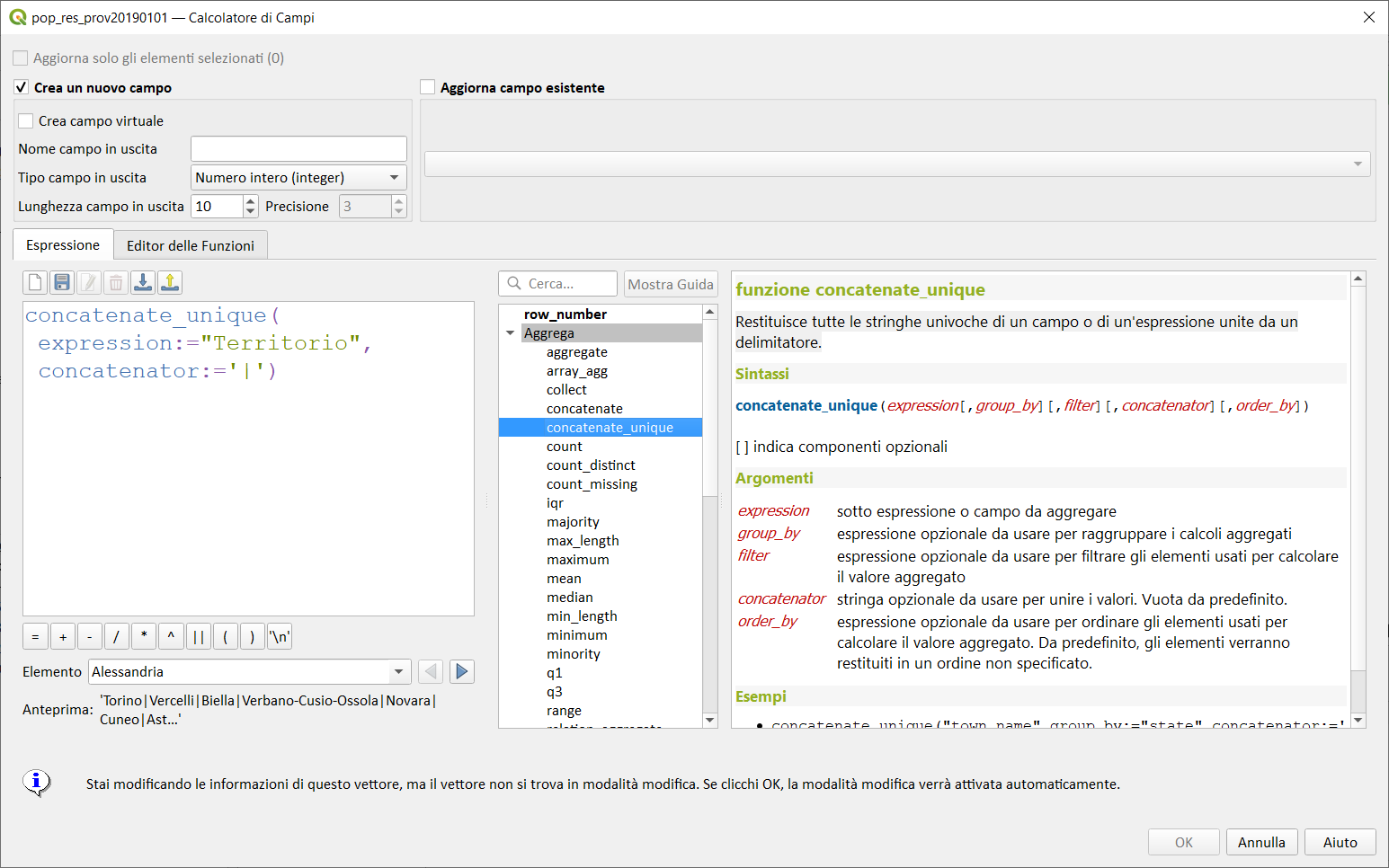
concatenate_unique↵
Restituisce tutte le stringhe univoche di un campo o di un'espressione unite da un delimitatore.
Sintassi:
- concatenate(expression[,group_by][,filter][,concatenator][,order_by])
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
- concatenator stringa opzionale da usarsi per unire i valori
- order_by espressione opzionale da usare per ordinare gli elementi usati per calcolare il valore aggregato. Da predefinito, gli elementi verranno restituiti in un ordine non specificato.
[ ] indica componenti opzionali
Esempi:
concatenate_unique("town_name",group_by:="state",concatenator:=',') → lista separata da virgola di town_names univoci, raggruppata per campo state
count↵
Restituisce il conteggio degli elementi corrispondenti.
Sintassi:
- count(expression[,group_by][,filter])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
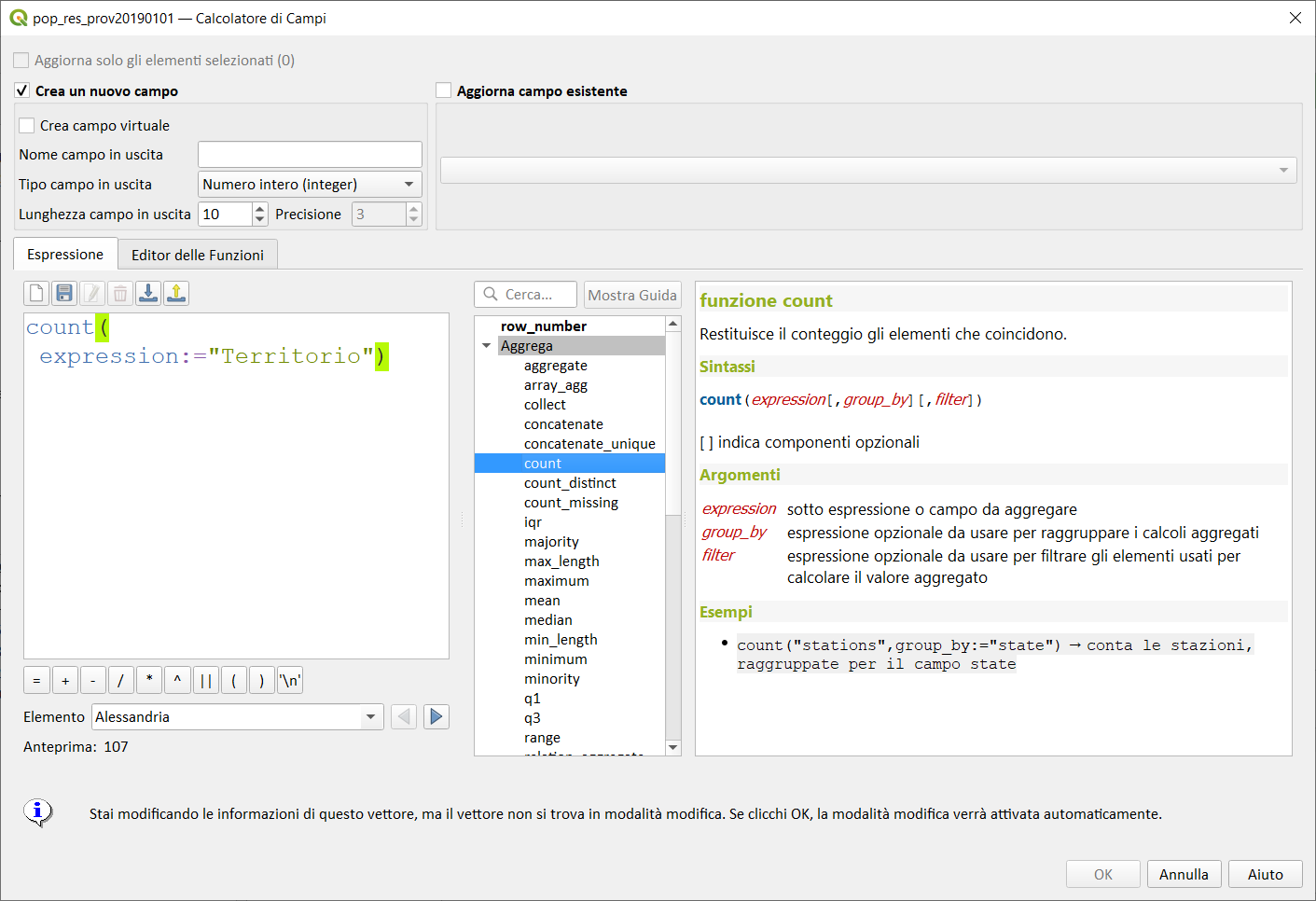
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- count(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- count(filter:= ,expression:= ,group_by:= )
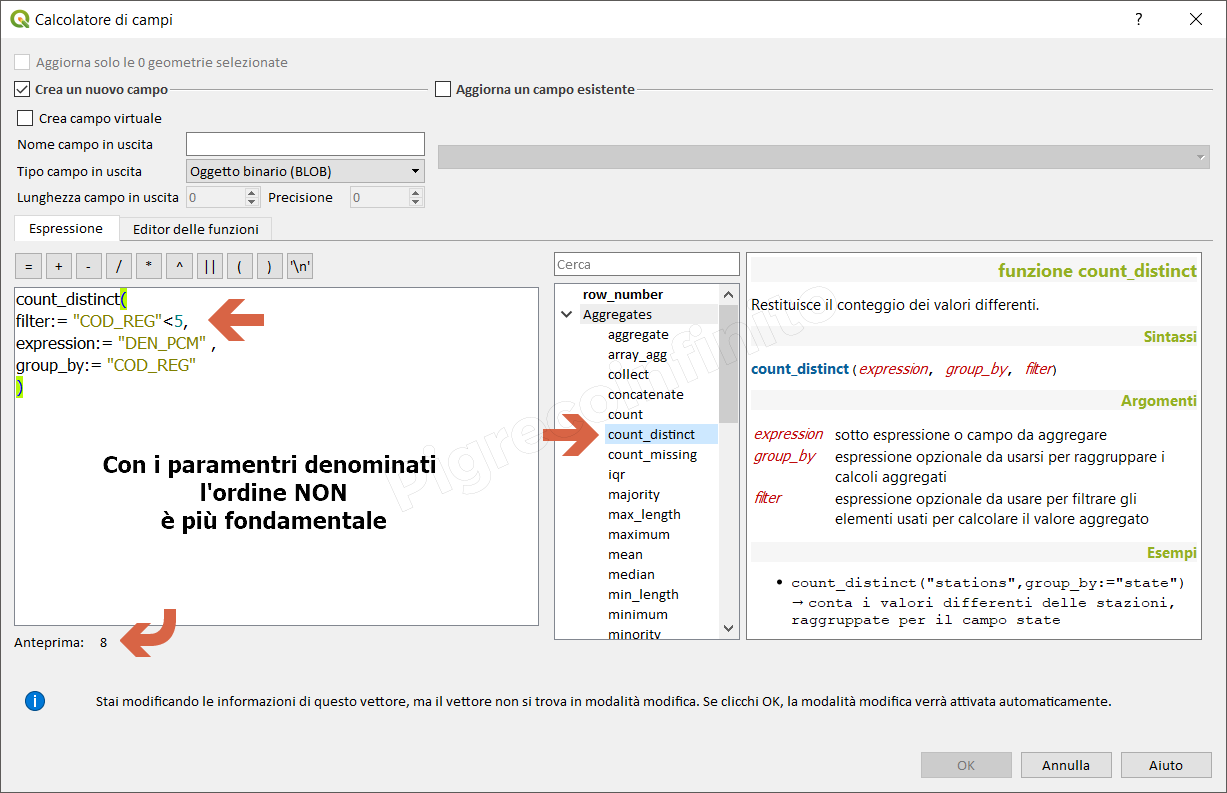
count_distinct↵
Restituisce il conteggio dei valori differenti.
Sintassi:
- count_distinct(expression[,group_by][,filter])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
count_distinct("stations",group_by:="state") → conta i valori differenti delle stazioni, raggruppate per il campo state

Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- count_distinct(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- count_distinct(filter:= ,expression:= ,group_by:= )
--
count_missing↵
Restituisce il numero di valori nulli (NULL).
Sintassi:
- count_missing(expression[,group_by][,filter])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
count_missing("stations",group_by:="state") → conta i valori mancanti (NULL) delle stazioni, raggruppati per il campo state
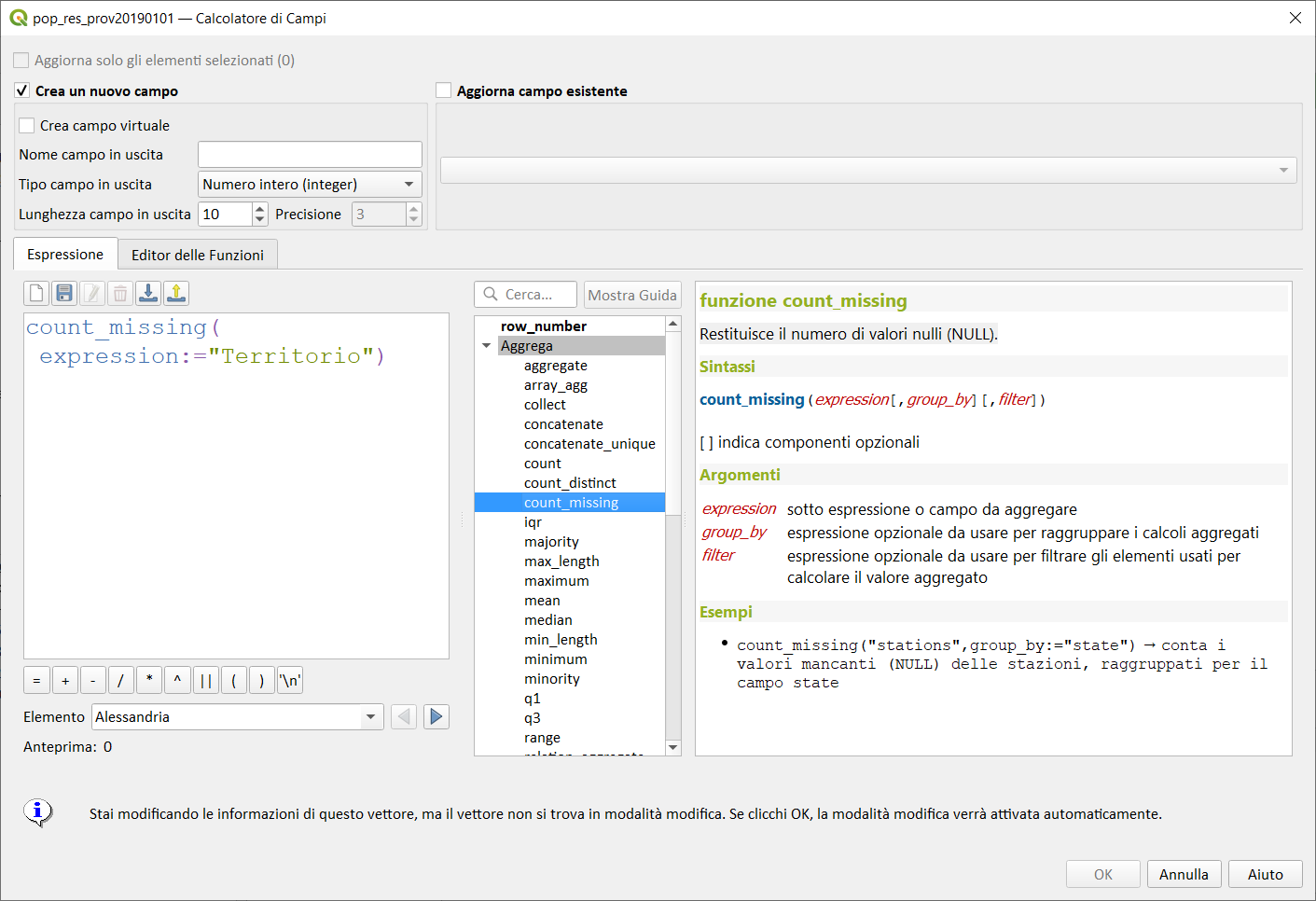
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- count_missing(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- count_missing(filter:= ,expression:= ,group_by:= )
iqr↵
Restituisce lo scarto interquartile calcolato da un campo o espressione.
Sintassi:
- iqr(expression[,group_by][,filter])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
iqr("population",group_by:="state") → scarto interquartile del valore popolazione, raggruppato per il campo state
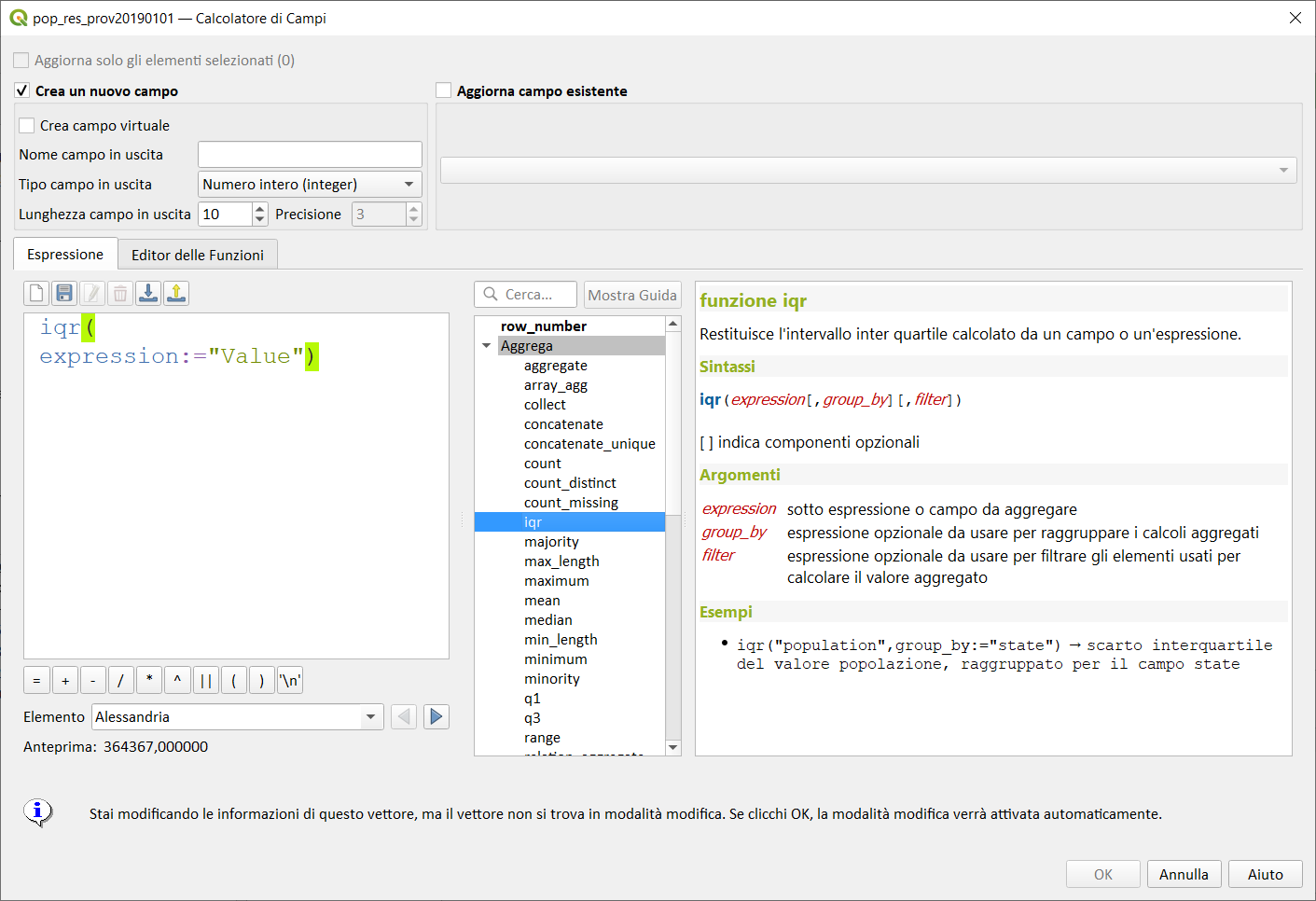
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- iqr(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- iqr(filter:= ,expression:= ,group_by:= )
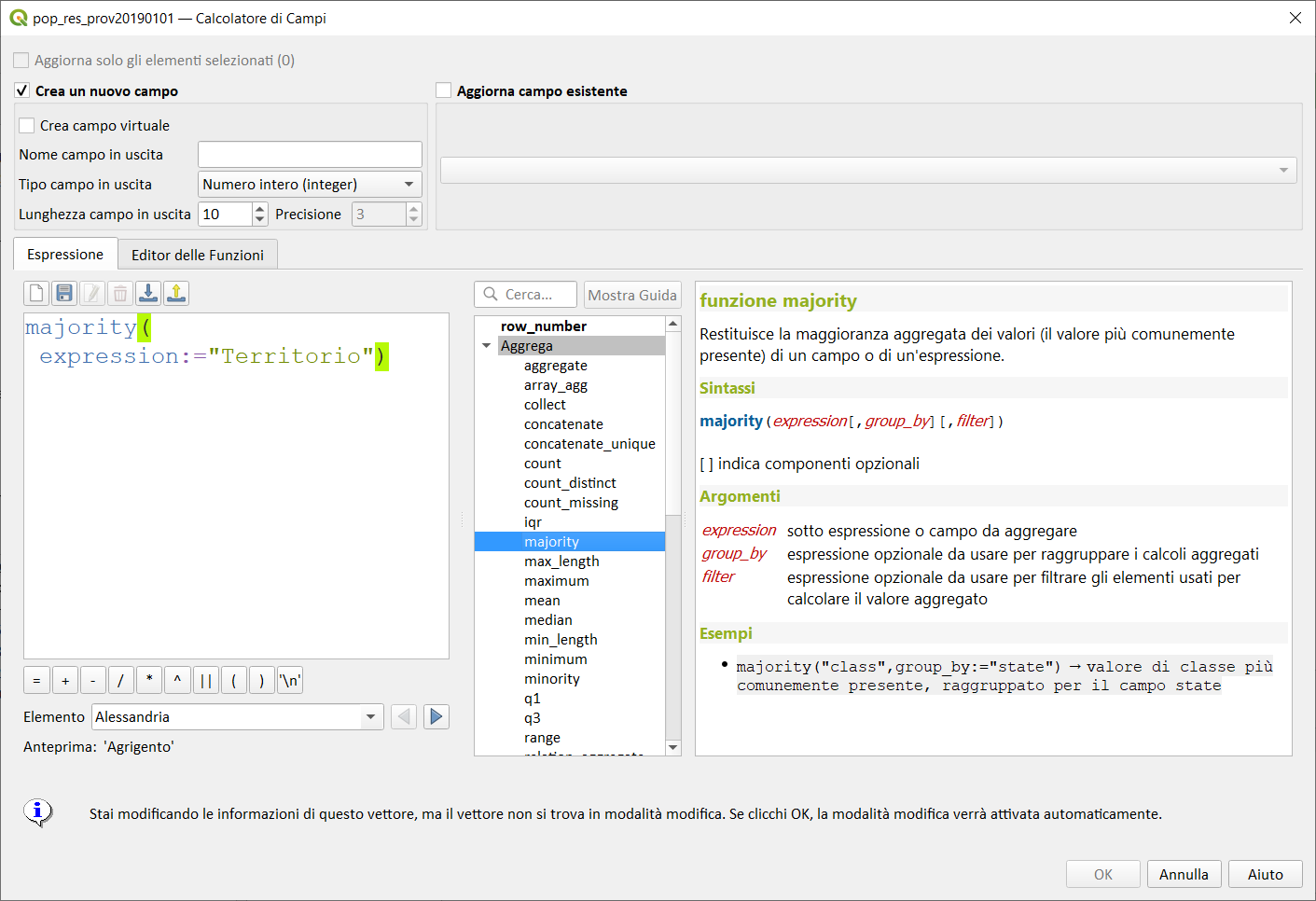
majority↵
Restituisce la maggioranza aggregata di valori (valore più comunemente presente) da un campo o espressione.
Sintassi:
- majority(expression[,group_by][,filter])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
majority("class",group_by:="state") → valore di classe più comunemente presente, raggruppato per il campo state
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- majority(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- majority(filter:= ,expression:= ,group_by:= )
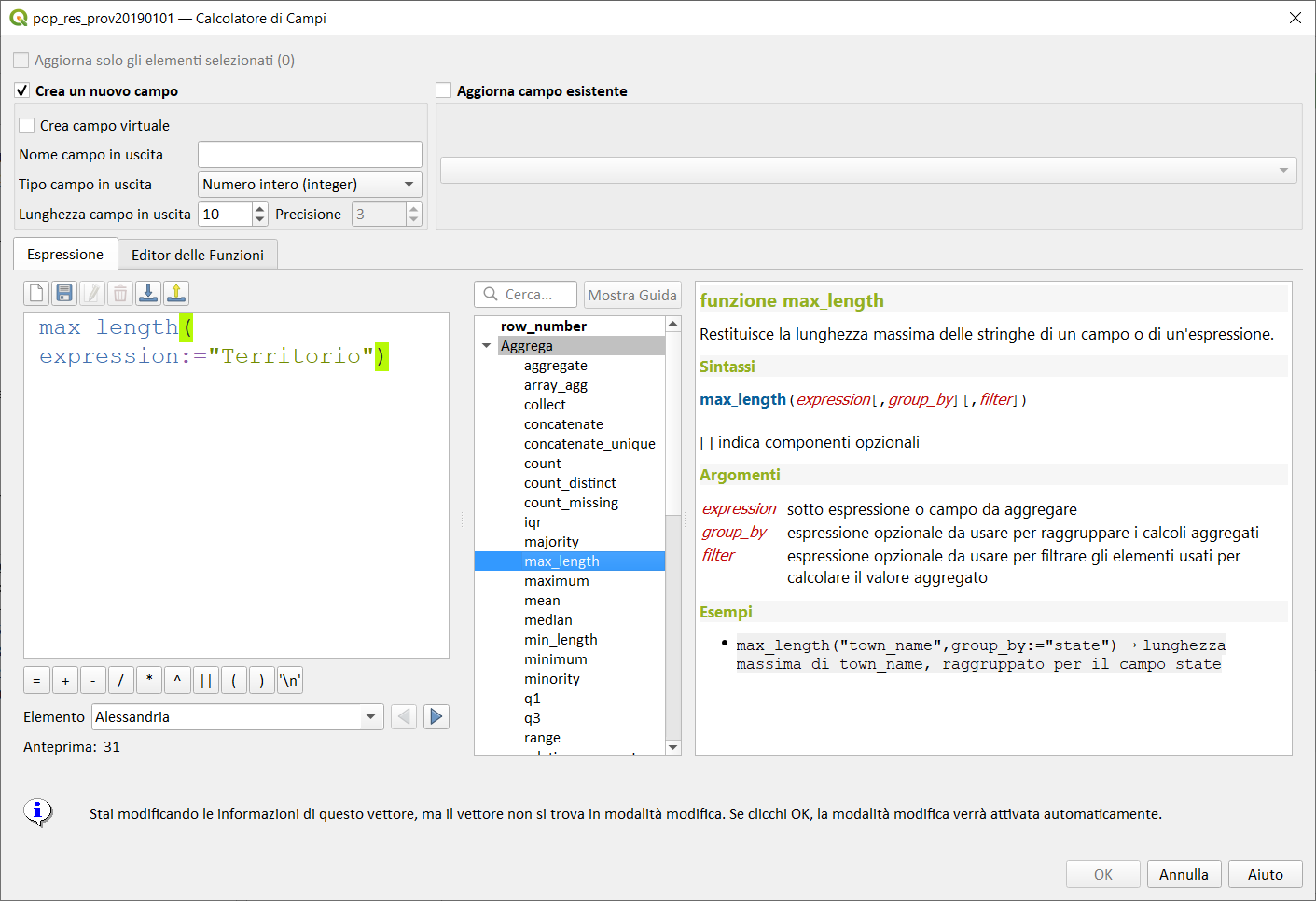
max_length↵
Restituisce la lunghezza massima delle stringhe di un campo o espressione.
Sintassi:
- max_length(expression[,group_by][,filter])
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
max_length("town_name",group_by:="state") → lunghezza massima di town_name, raggruppato per il campo state
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- max_length(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- max_length(filter:= ,expression:= ,group_by:= )
maximum↵
Restituisce il valore massimo aggregato da un campo o espressione.
Sintassi:
- maximum(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
maximum("population",group_by:="state") → valore massimo di population, raggruppato per il campo state

Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- maximum(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- maximum(filter:= ,expression:= ,group_by:= )
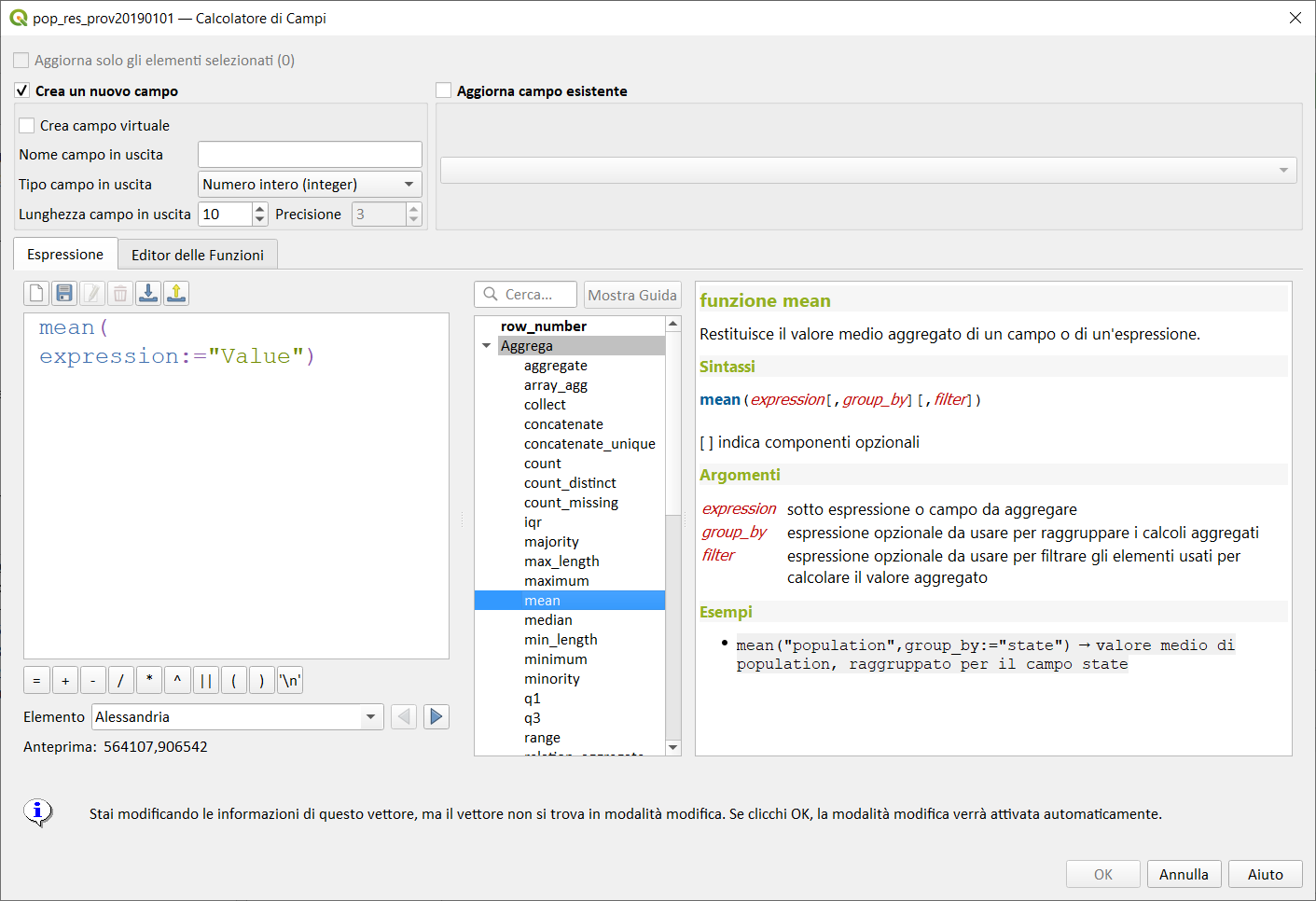
mean↵
Restituisce il valore medio aggregato da un campo o espressione.
Sintassi:
- mean(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- mean(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- mean(filter:= ,expression:= ,group_by:= )
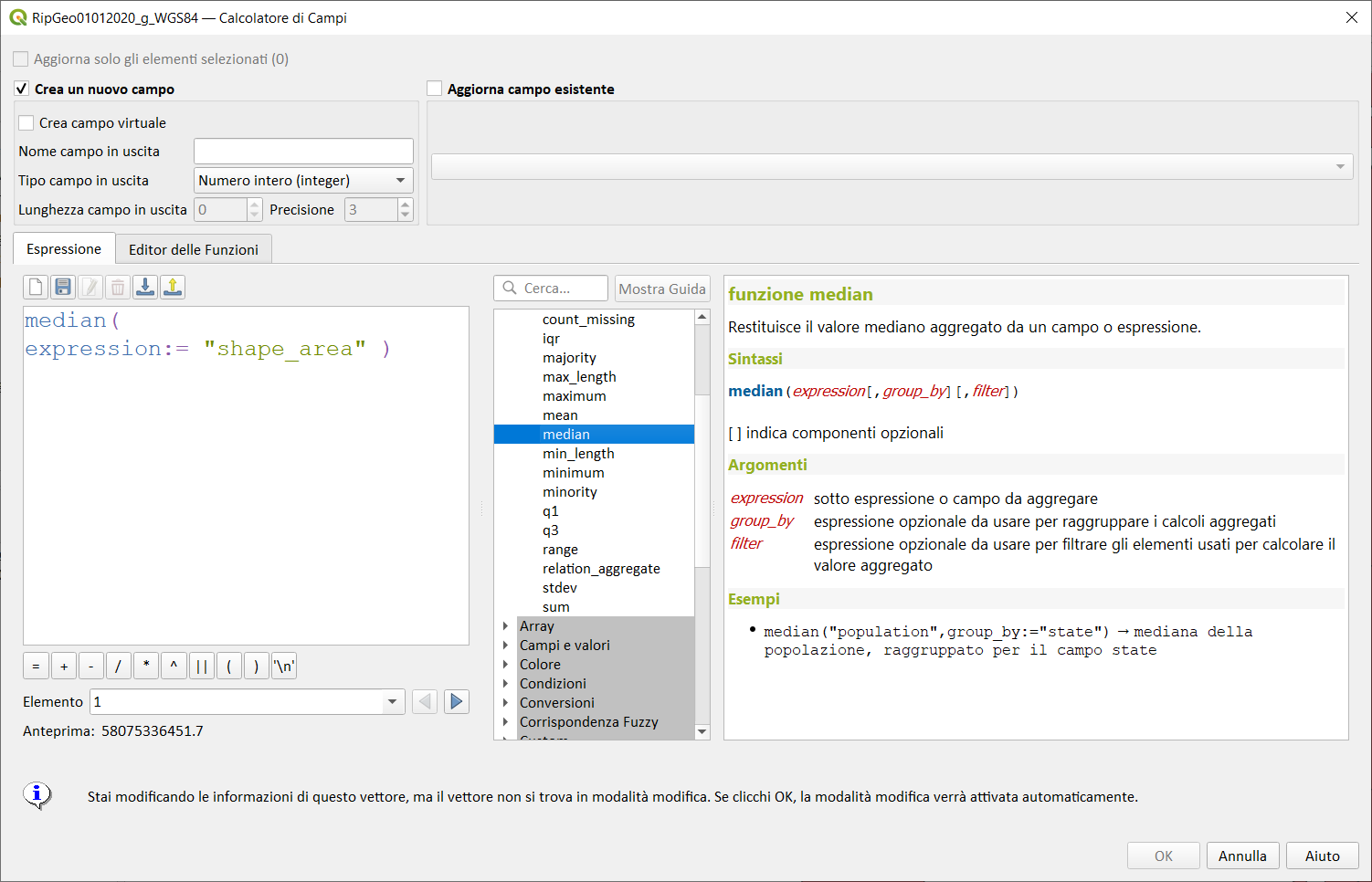
median↵
Restituisce il valore mediano aggregato da un campo o espressione.
Sintassi:
- median(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- median(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- median(filter:= ,expression:= ,group_by:= )
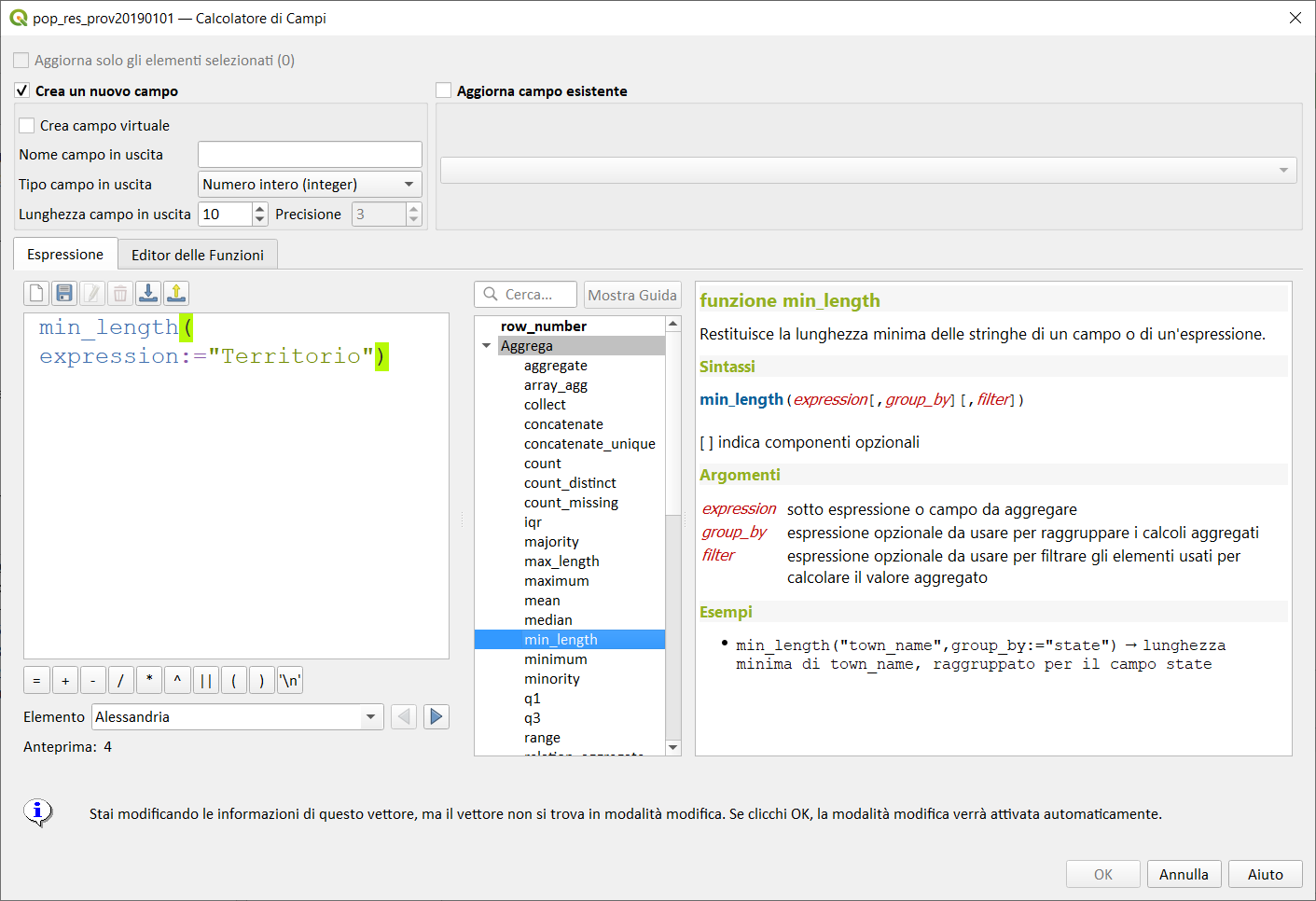
min_length↵
Restituisce la lunghezza minima delle stringhe di un campo o espressione.
Sintassi:
- min_length(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
min_length("town_name",group_by:="state") → lunghezza minima di town_name, raggruppato per il campo state
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- min_length(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- min_length(filter:= ,expression:= ,group_by:= )
minimum↵
Restituisce il valore minimo aggregato da un campo o espressione.
Sintassi:
- minimum(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
minimum("population",group_by:="state") → valore minimo di population, raggruppato per il campo state

Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- minimum(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- minimum(filter:= ,expression:= ,group_by:= )
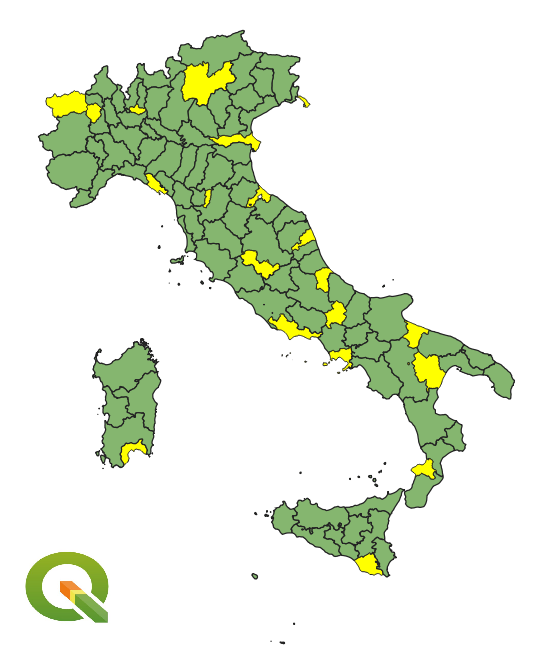
Esempio:
Selezionare le Province con minor area per ogni Regione
$area = minimum(expression:=$area,group_by:="COD_REG")
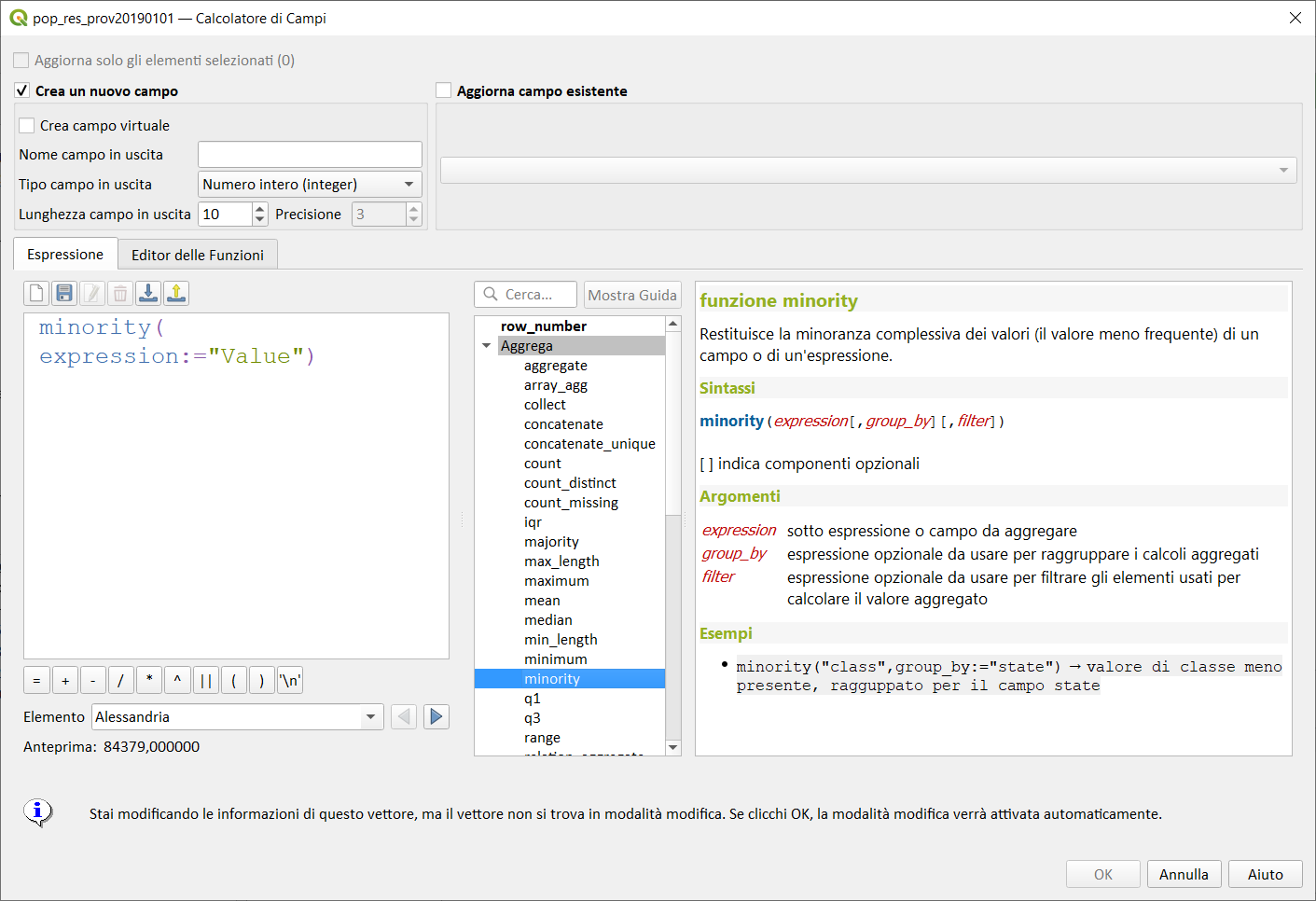
minority↵
Restituisce la minoranza aggregata di valori (valore meno comunemente presente) da un campo o espressione.
Sintassi:
- minority(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- minority(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- minority(filter:= ,expression:= ,group_by:= )
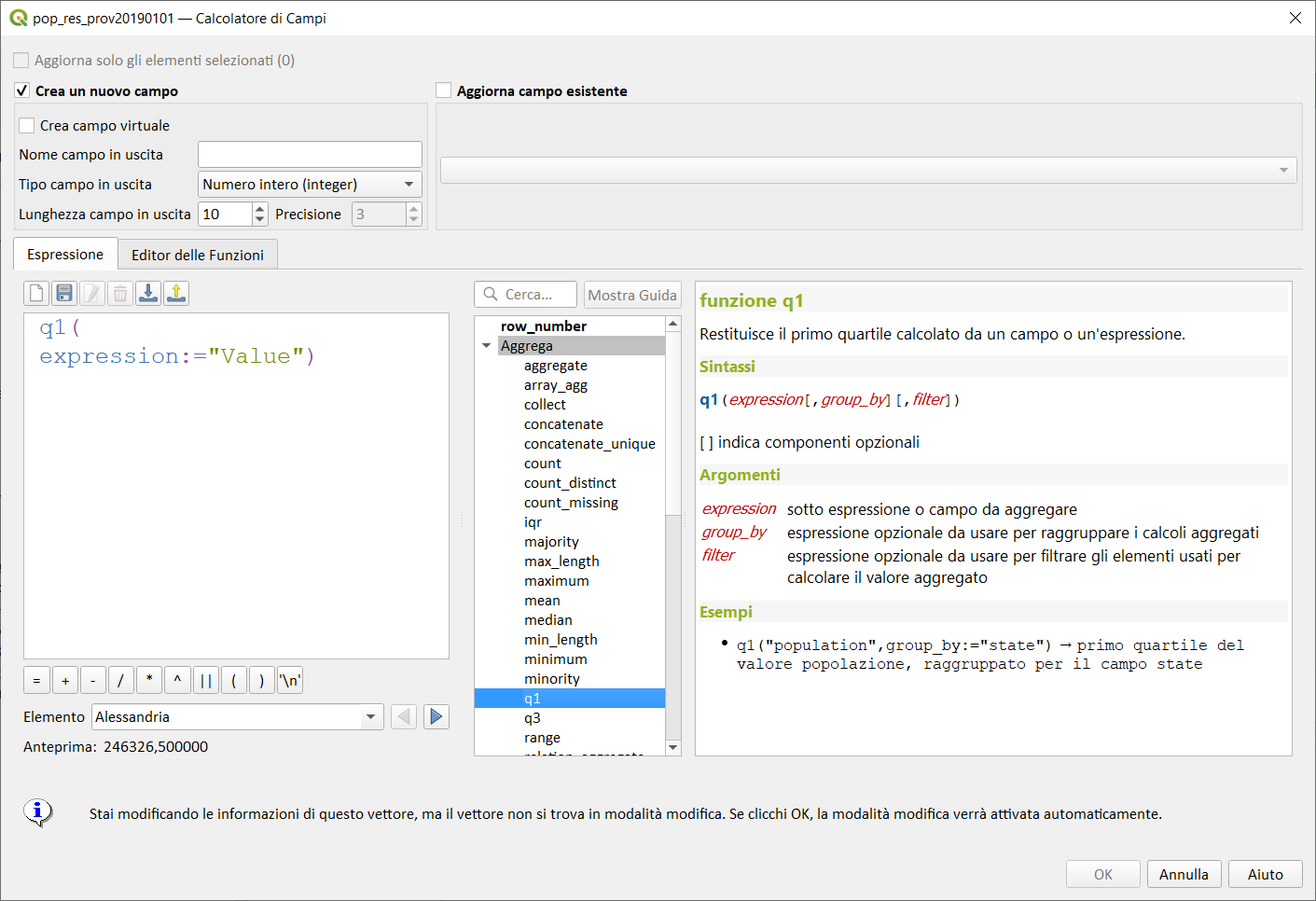
q1↵
Restituisce il primo quartile calcolato da un campo o espressione.
Sintassi:
- q1(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
q1("population",group_by:="state") → primo quartile del valore popolazione, raggruppato per il campo state
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- q1(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- q1(filter:= ,expression:= ,group_by:= )
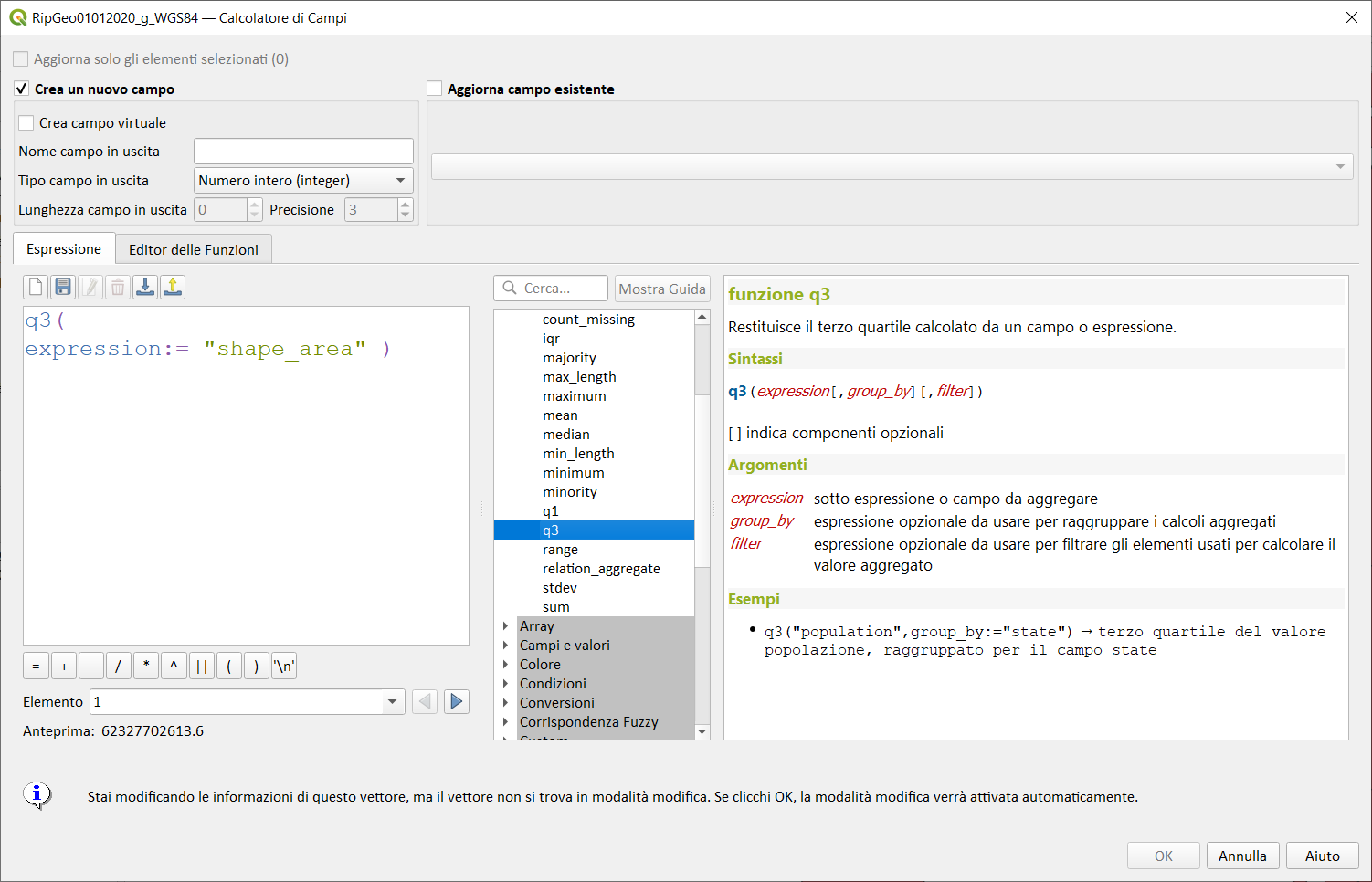
q3↵
Restituisce il terzo quartile calcolato da un campo o espressione.
Sintassi:
- q3(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
q3("population",group_by:="state") → terzo quartile del valore popolazione, raggruppato per il campo state
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- q3(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- q3(filter:= ,expression:= ,group_by:= )
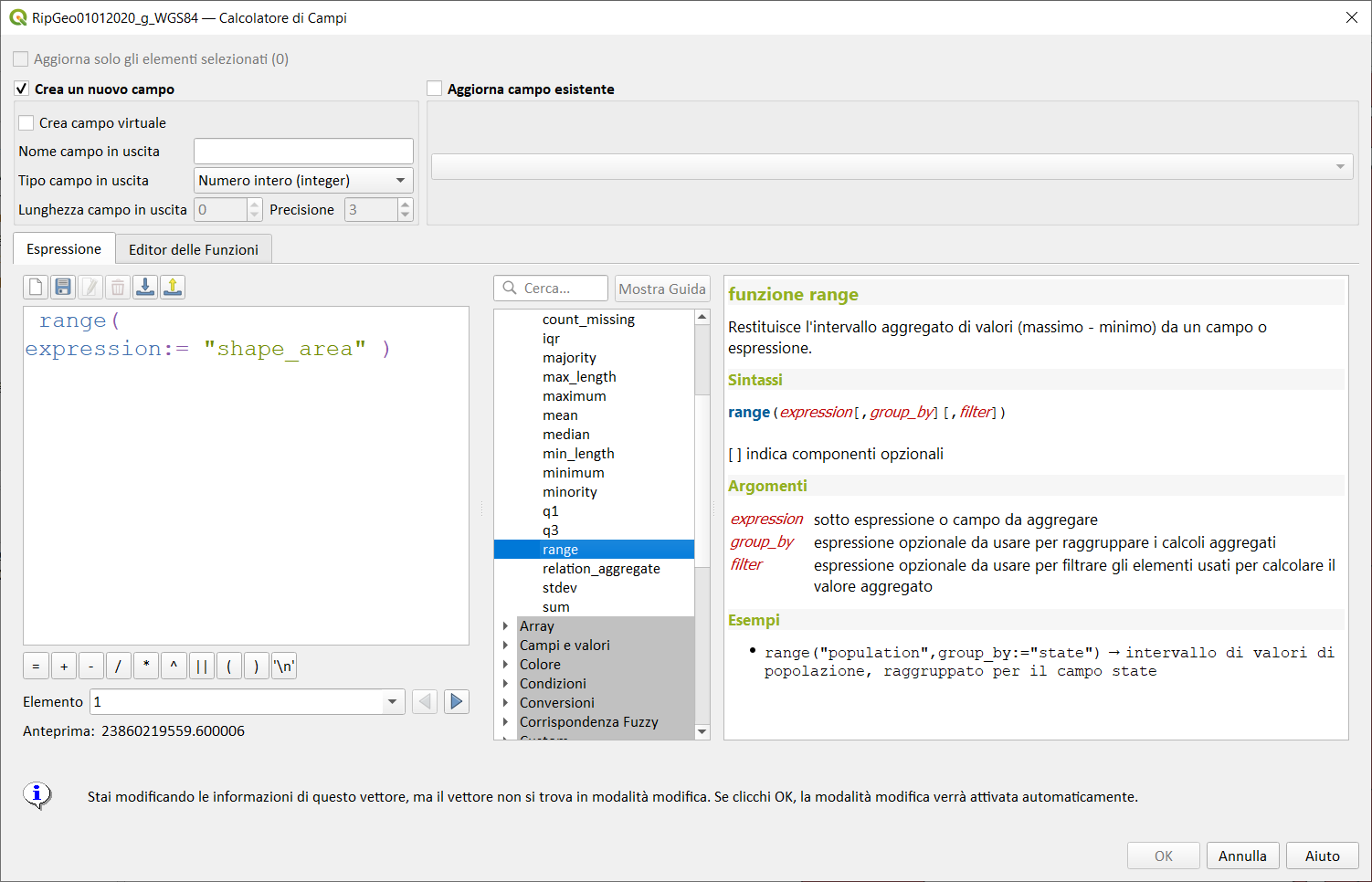
range↵
Restituisce l'intervallo aggregato di valori (massimo - minimo) da un campo o espressione.
Sintassi:
- range(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
range("population",group_by:="state") → intervallo di valori di popolazione, raggruppato per il campo state
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- range(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- range(filter:= ,expression:= ,group_by:= )
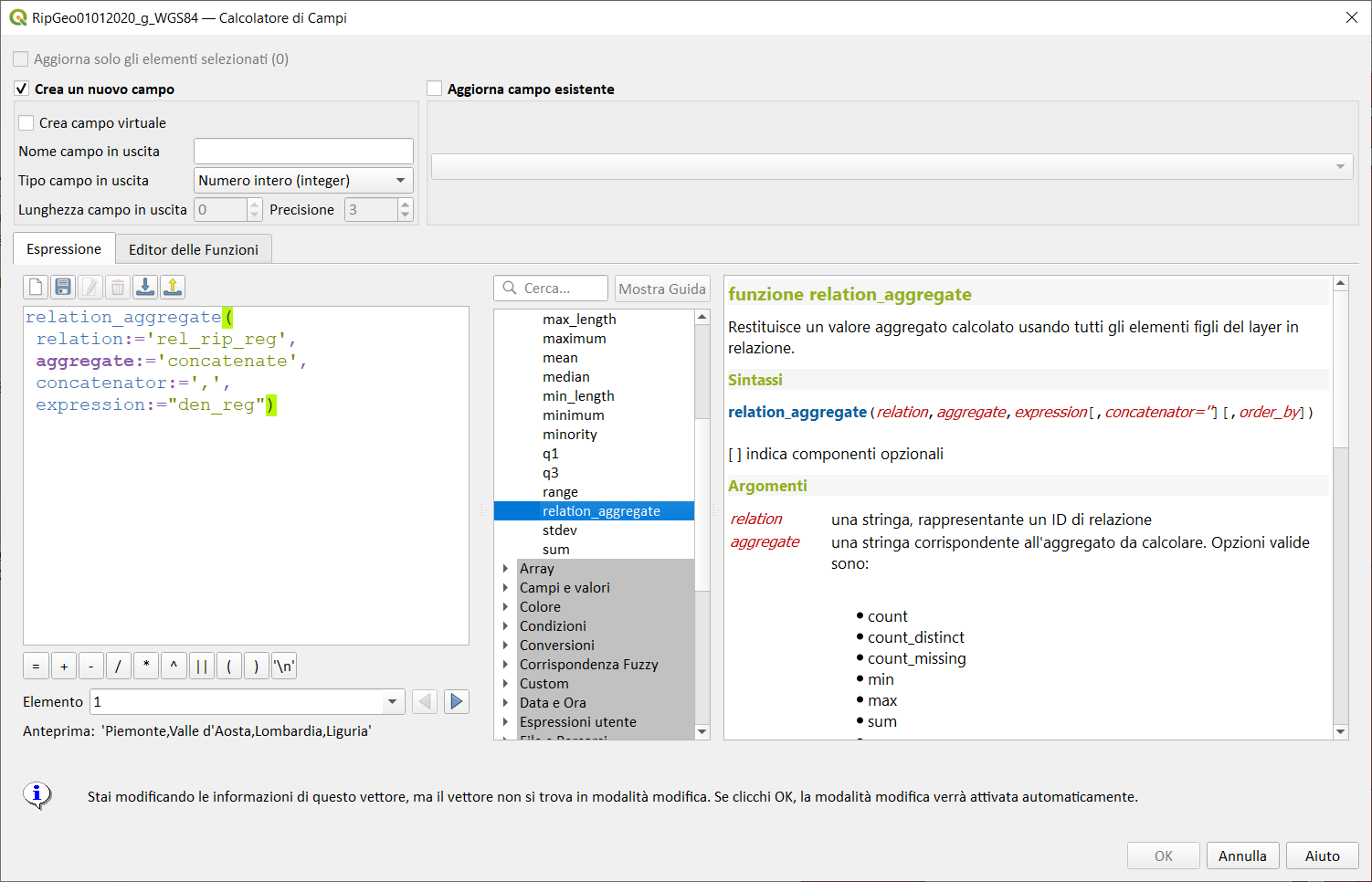
relation_aggregate↵
Restituisce un valore aggregato calcolato usando tutti gli elementi figli corrispondenti da una relazione di layer.
Sintassi:
- relation_aggregate(relation, aggregate, expression[,concatenator][,order_by])
Argomenti:
- relation una stringa, rappresentante un ID di relazione
-
aggregate una stringa corrispondente all'aggregato da calcolare. Opzioni valide sono:
- count
- count_distinct
- count_missing
- minimun or min (>= QGIS 3.36)
- maximun or max (>= QGIS 3.36)
- sum
- mean
- median
- stdev
- stdevsample
- range
- minority
- majority
- q1: primo quartile
- q3: terzo quartile
- iqr: scarto interquartile
- min_length: minima lunghezza stringa
- max_length: massima lunghezza stringa
- concatenate: unisci stringhe con un concatenatore
-
expression sotto espressione o nome campo da aggregare
- concatenator stringa opzionale da usare per unire i valori per il raggruppamento 'concatenate'
- order_by espressione filtro opzionale atta ad ordinare gli elementi usati per calcolare il valore aggregato. Campi e geometria provengono dagli elementi del vettore unito. In modo predefinito, gli elementi verranno restituiti senza un ordine specifico.
Esempi:
relation_aggregate(relation:='my_relation',aggregate:='mean',expression:="passengers") → valore medio di tutti gli elementi figli corrispondenti usando la relazione 'my_relation'
relation_aggregate('my_relation','sum', "passengers"/7) → somma del campo passengers diviso per 7 per tutti gli elementi figli corrispondenti usando la relazione 'my_relation'
relation_aggregate('my_relation','concatenate', "towns", concatenator:=',') → elenco separato da virgole del campo towns per tutte le geometrie figlie corrispondenti che usano la relation 'my_relation'
relation_aggregate('my_relation','array_agg', "id") → array del campo id derivato da tutti gli elementi figlio corrispondenti usando la relazione 'my_relation'
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- relation_aggregate(relation, aggregate, expression[,concatenator][,order_by])
-
con i parametri denominati (l'ordine non è più fondamentale):
- relation_aggregate(filter:= ,expression:= ,group_by:= )
--
stdev↵
Restituisce il valore di deviazione standard aggregato da un campo o espressione.
Sintassi:
- stdev(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
stdev("population",group_by:="state") → deviazione standard di un valore popolazione, raggruppato per il campo state

Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- stdev(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- stdev(filter:= ,expression:= ,group_by:= )
sum↵
Restituisce il valore sommato aggregato da un campo o espressione.
Sintassi:
- sum(expression, group_by, filter)
[ ] indica componenti opzionali
Argomenti:
- expression sotto espressione o campo da aggregare
- group_by espressione opzionale da usarsi per raggruppare i calcoli aggregati
- filter espressione opzionale da usare per filtrare gli elementi usati per calcolare il valore aggregato
Esempi:
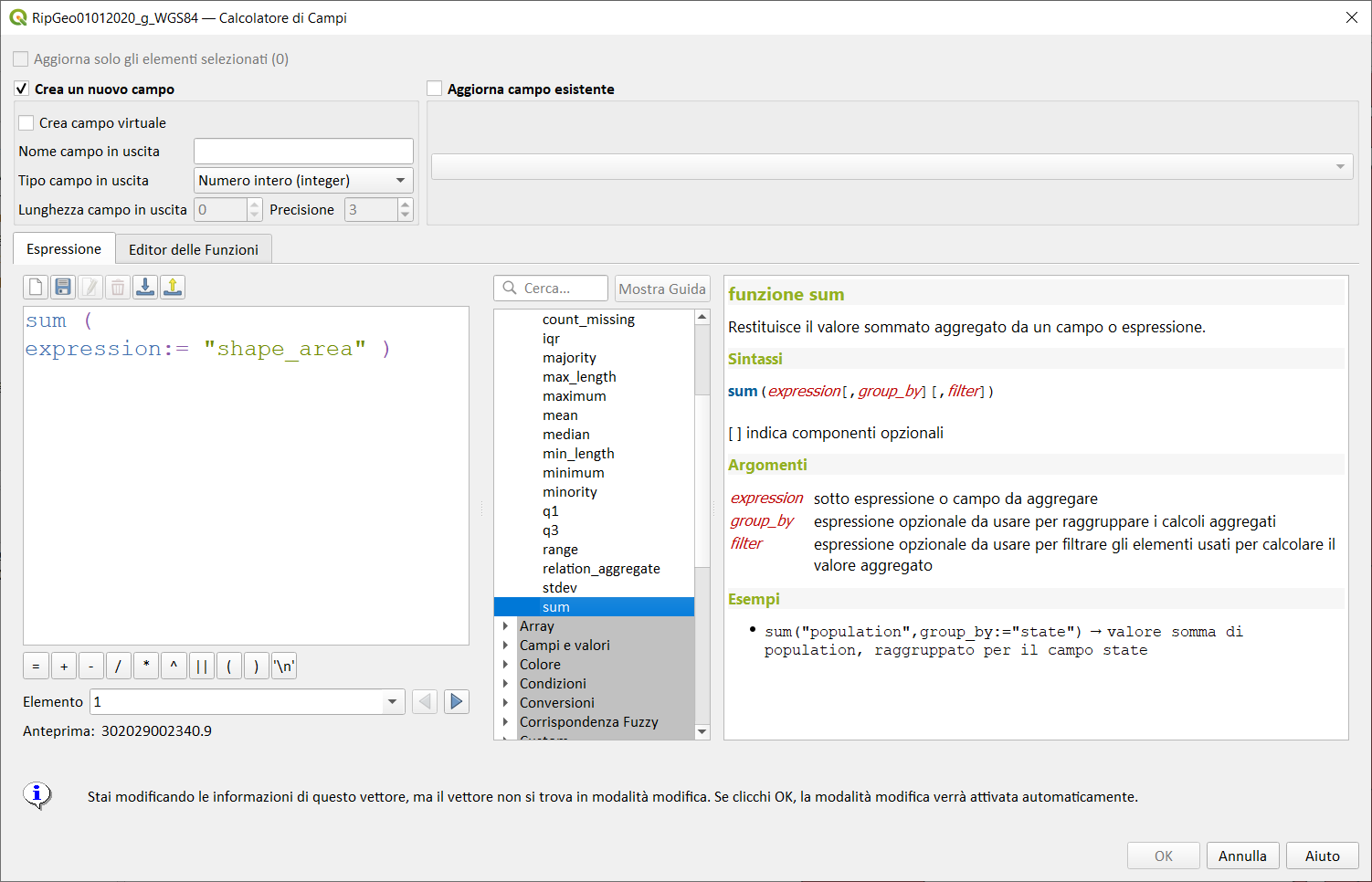
Nota bene:
La sintassi prevede due possibilità:
-
quella classica, senza l'uso dei paramentri denominati (l'ordine è fondamentale);
- stdev(expression, group_by, filter)
-
con i parametri denominati (l'ordine non è più fondamentale):
- stdev(filter:= ,expression:= ,group_by:= )